|
I am an AI Research Scientist at the Meta Superintelligence Labs (MSL). My current work spans AI agents, multimodal language modeling, reinforcement learning, and video understanding, with background in 3D vision and embodied AI. Prior to joining MSL, I was a Research Scientist at Meta Reality Labs and the Microsoft Mixed Reality & AI Lab in Zürich. I received my PhD in the Computer Vision Laboratory of EPFL, advised by Prof. Pascal Fua and Prof. Vincent Lepetit. My academic background includes an MS from EPFL, a BS from Bogazici University with high honors, and research stints at Microsoft Research and ETH Zürich. I am also a recipient of the 2017 Qualcomm Innovation Fellowship Europe. |

|
|
My core research centers on bridging the gap between visual perception and agency. Having developed a strong foundational expertise in 3D computer vision and spatial understanding, my recent focus has expanded into training AI agents, reinforcement learning, and multimodal language modeling. My primary motivation is to connect deep visual perception with robust decision-making to close the full loop of intelligent systems. Previously, much of my work has explored how to semantically understand humans and objects in the 3D world, including extensive research in human-object interactions, 2D/3D human and hand pose estimation, action recognition, and 6D object pose estimation. By combining this rich perceptual grounding with advanced agentic models, I am interested in building versatile AI systems capable of perceiving, reasoning, and acting across a wide variety of domains, with natural applications spanning from software agents to embodied AI. |
|
|
|
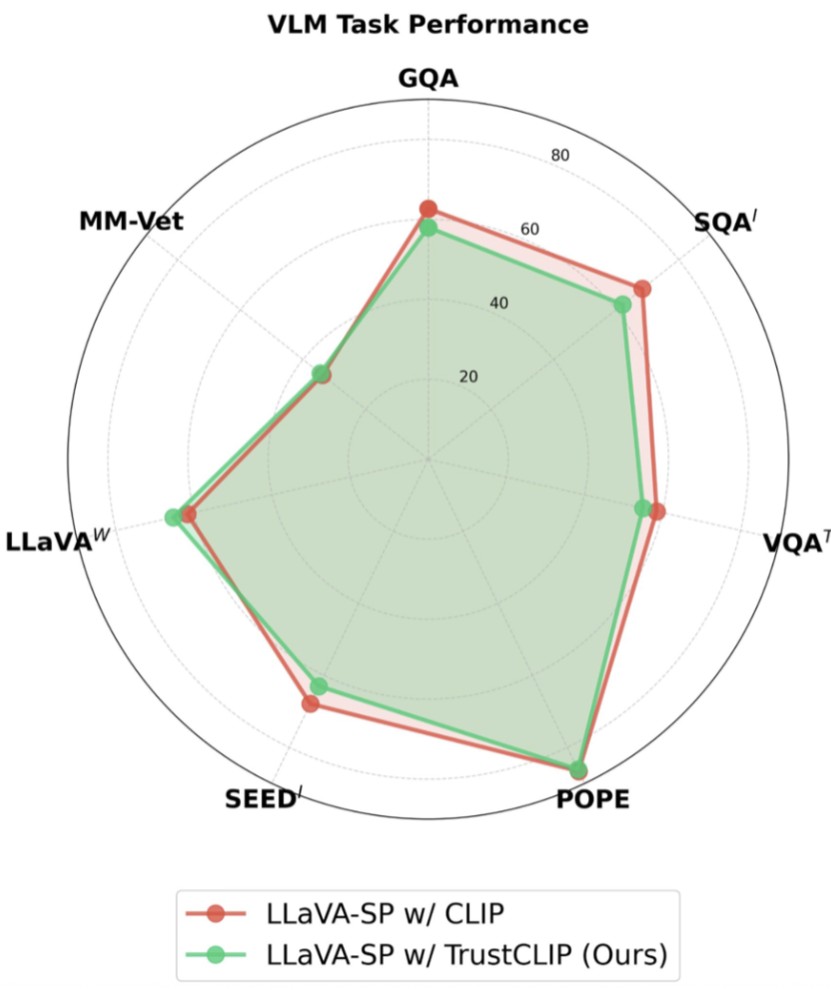
To secure the next generation of foundational vision models against the critical privacy threats, we introduce a novel approach to privacy-preserving visual representation learning. We present three key contributions: (1) TrustCLIP, a powerful reconstruction-driven framework that treats generative attackers as explicit adversaries, redefining how secure visual features are learned; (2) a scalable optimization strategy—designed for seamless integration into visual encoder pretraining—that actively dismantles sensitive reconstructable details while fully preserving the essential semantic signals required for complex AI tasks; and (3) robust evaluations across classification and multimodal large language model pipelines, demonstrating that TrustCLIP fundamentally neutralizes high-fidelity data extraction without compromising downstream capabilities. |

|
We introduce the novel task of egocentric self-emotion tracking through three key contributions: (1) the OSMO dataset, the largest egocentric emotion dataset built on 110 hours of smart-glasses recordings; (2) the OSMO benchmark, which redefines emotion understanding as a continuous, context-aware process across five tasks; and (3) OSIRIS, a large multimodal model that tracks emotions over time by reasoning over the user’s personal history, current expressions, and egocentric observations. |
|
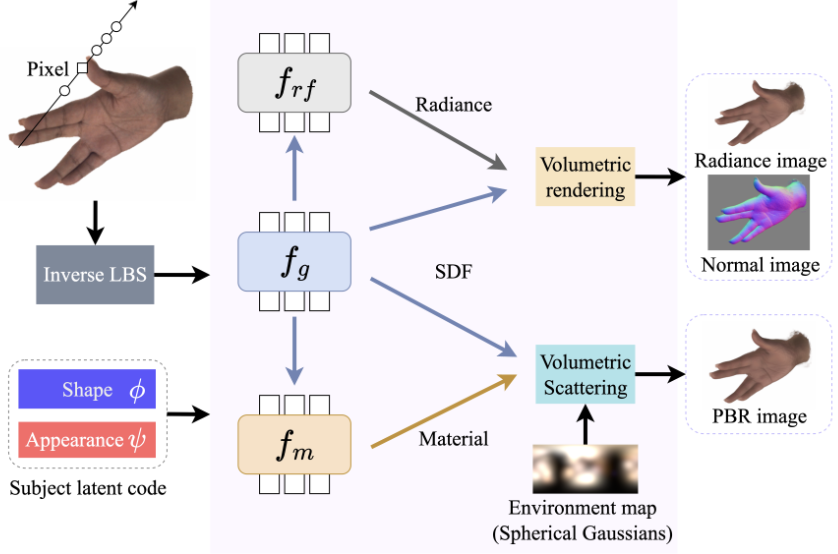
We present PALM, a large-scale hand dataset, along with PALM-Net, a physically based model enabling realistic single-image hand avatar personalization. |
|
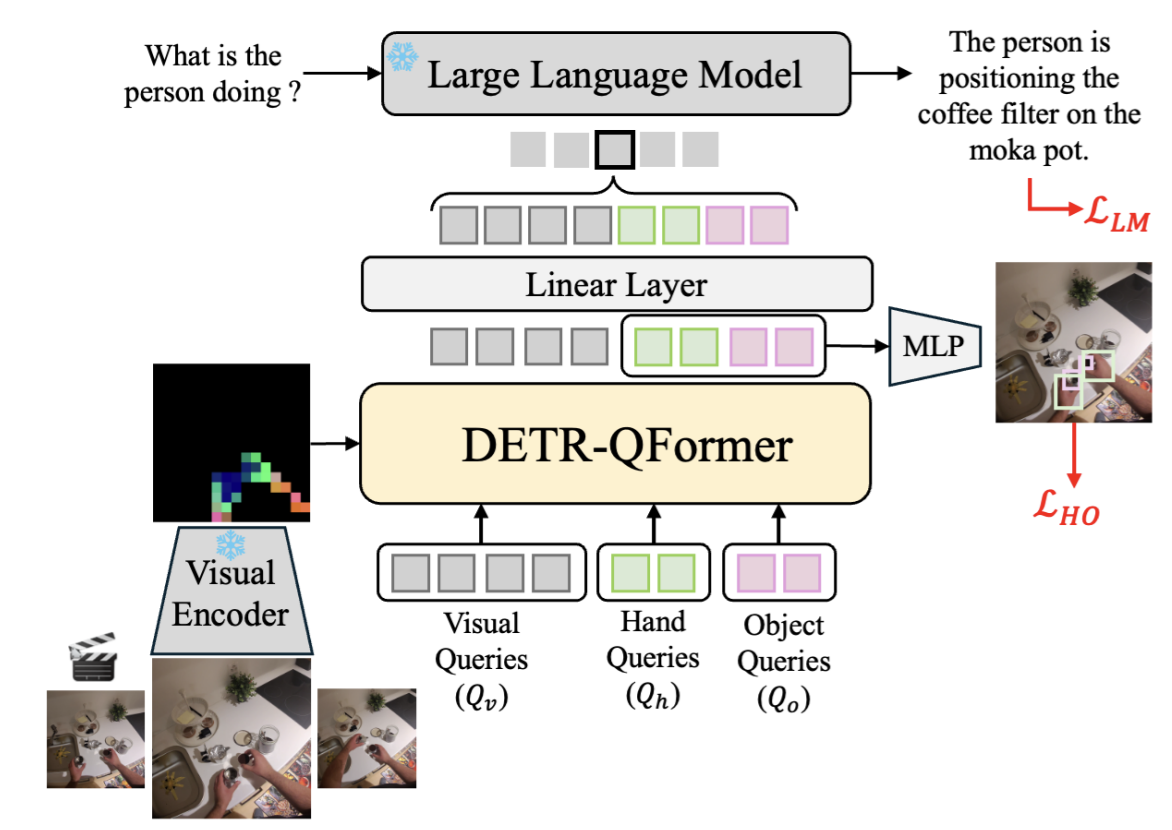
A streaming video large language model for real-time procedural video tasks with a low memory footprint. |
|
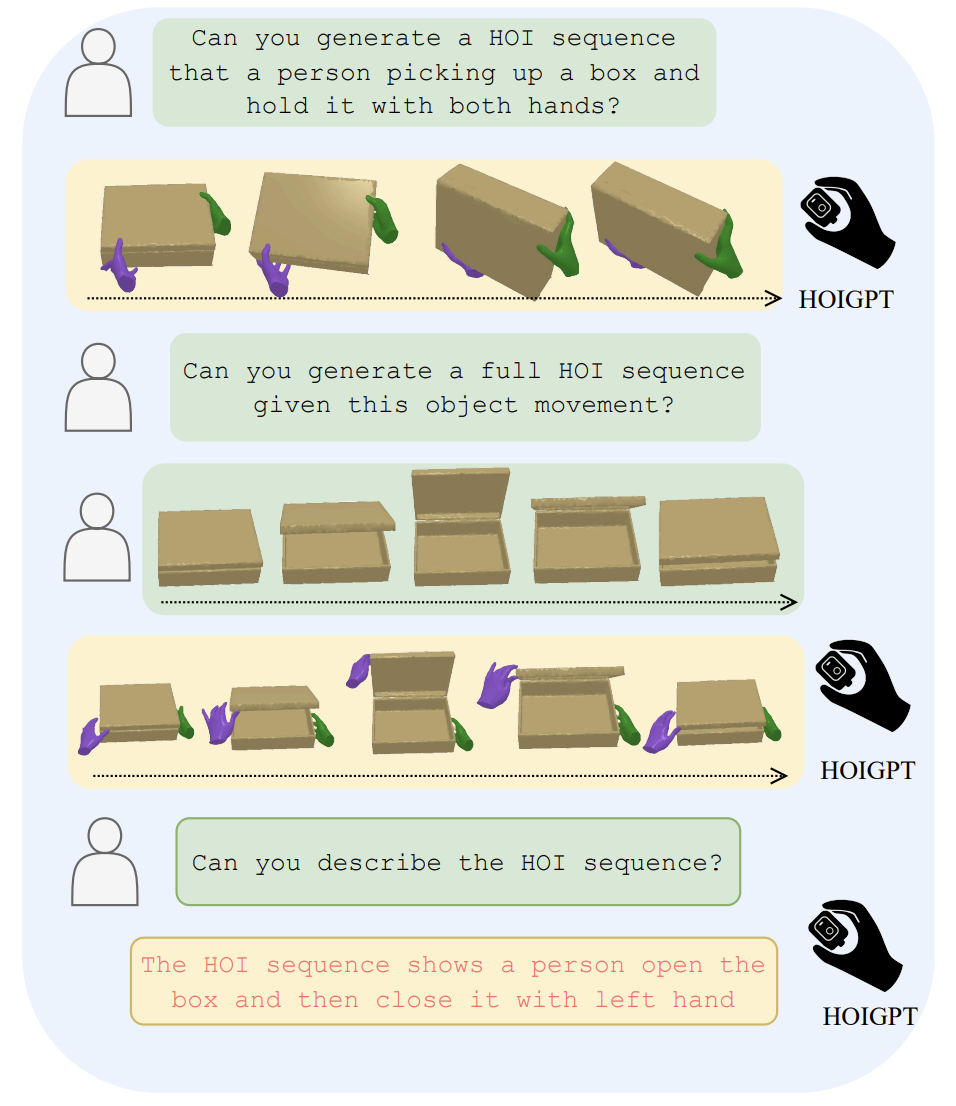
The first token-based generative model to unify both the understanding and generation of 3D hand-object interactions (HOI). |

|
For human action understanding with video-motion input, we propose HuMoCon, a framework designed to tackle feature misalignment and high-frequency information loss. HuMoCon enables effective motion concept discovery and enhances accuracy in Question Answering tasks. |

|
We introduce GoTrack, an efficient and accurate CAD-based method for 6DoF object pose refinement and tracking, which can handle diverse objects without any object-specific training. |

|
We introduce DiffH2O, a diffusion-based framework to synthesize dexterous hand-object interactions. DiffH2O generates realistic hand-object motion from natural language, generalizes to unseen objects at test time and enables fine-grained control over the motion with detailed textual descriptions |
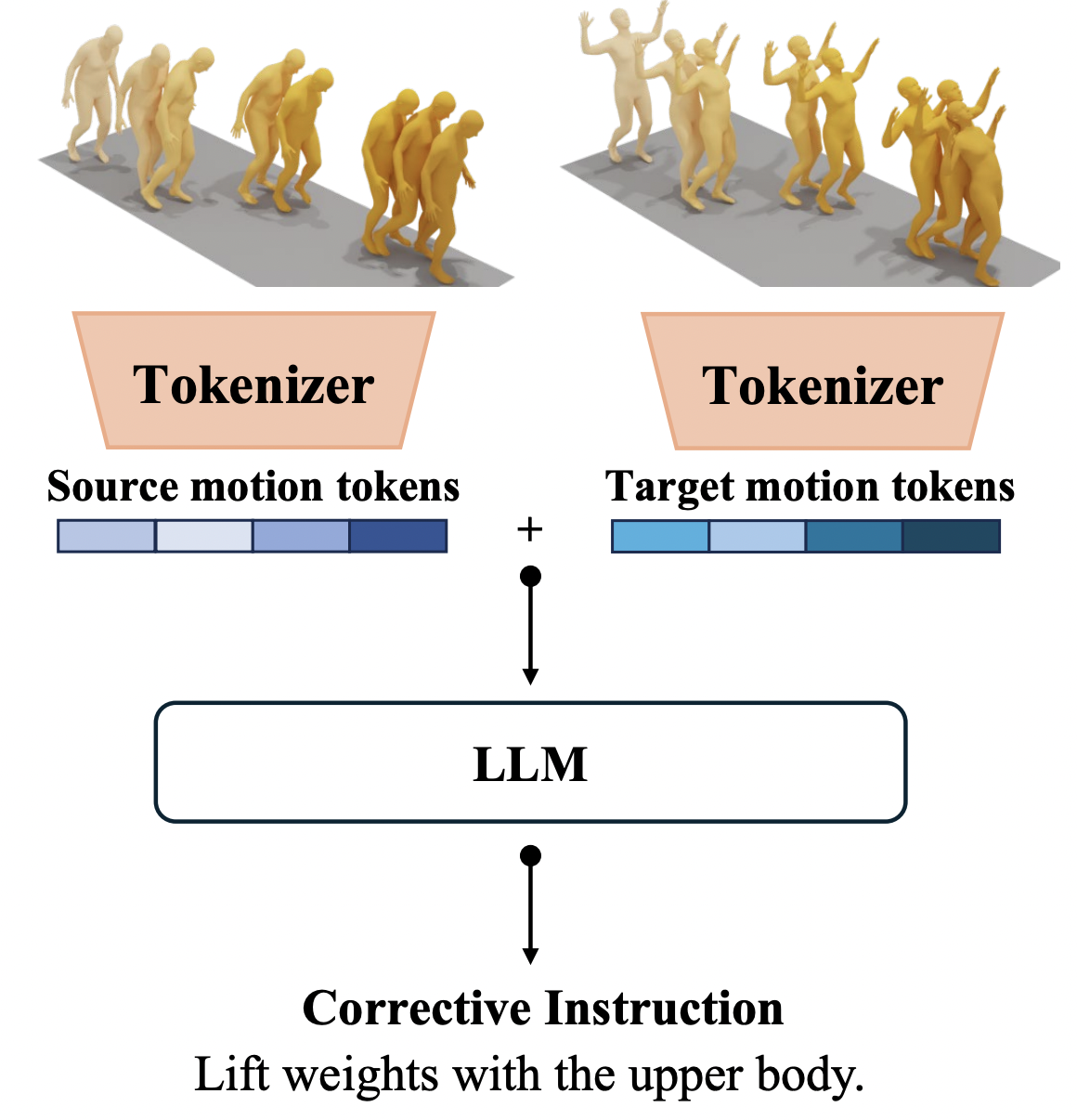
|
We introduce a novel task and system for automated coaching and feedback on human motion, aimed at generating corrective instructions and guidance for body posture and movement during specific tasks. |

|
A method for 6D pose estimation of unseen rigid objects from a single RGB image without any object-specific training. |
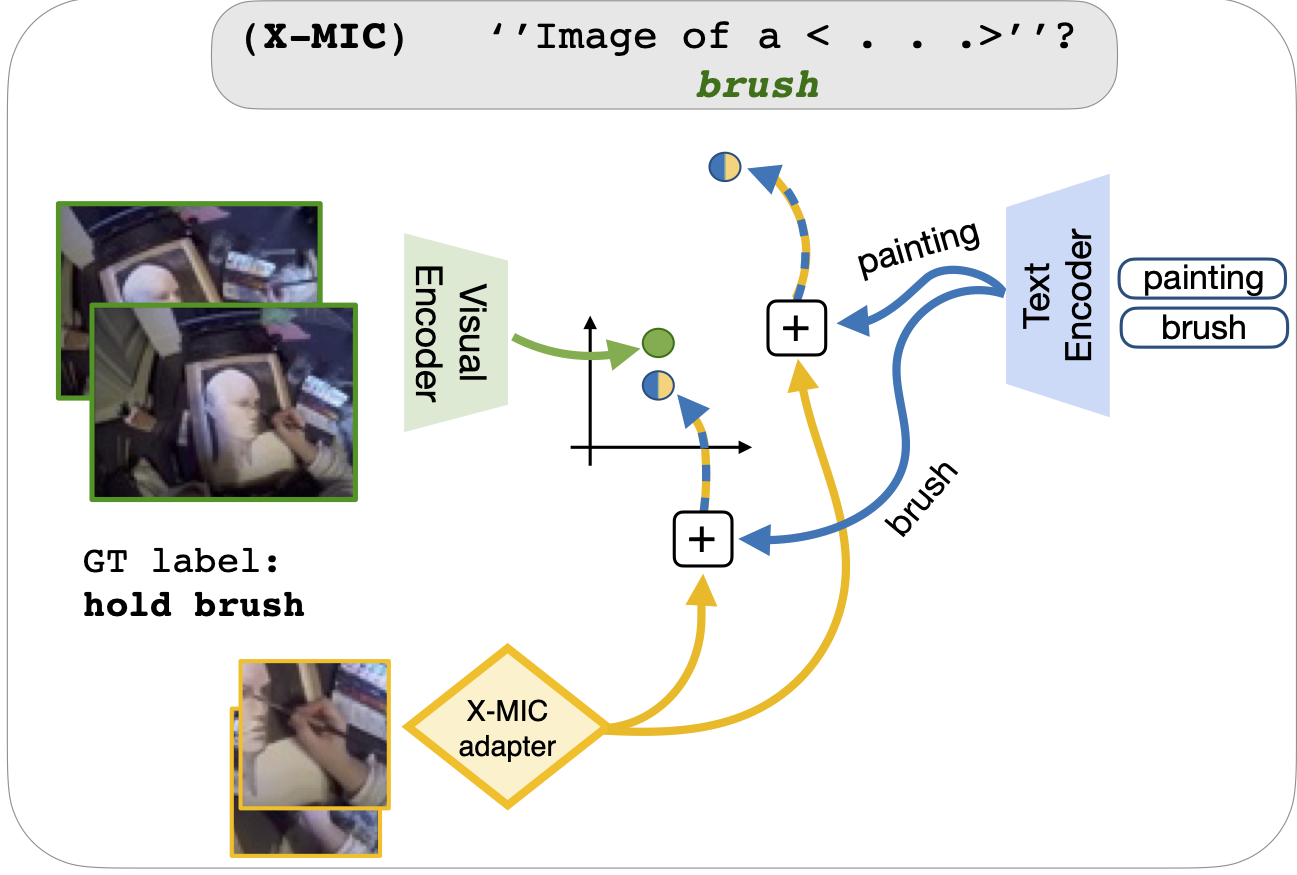
|
A simple yet effective cross-modal adaptation framework for VLMs. |

|
HoloAssist is a large-scale egocentric human interaction dataset, where two people collaboratively complete physical manipulation tasks. By augmenting the data with action and conversational annotations and observing the rich behaviors of various participants, we present key insights into how human assistants correct mistakes, intervene in the task completion procedure, and ground their instructions to the environment. |
|
We propose a skeletal self-supervised learning approach that uses alignment as a pretext task. Our approach to alignment relies on a context-aware attention model that incorporates spatial and temporal context within and across sequences and a contrastive learning formulation that relies on 4D skeletal augmentations. Pose data provides a valuable cue for alignment and downstream tasks, such as phase classification and phase progression, as it is robust to different camera angles and changes in the background, while being efficient for real-time processing. |

|
We propose an approach to align sequential actions in the wild that involve diverse temporal variations. To this end, we present a new method to enforce temporal priors on the optimal transport matrix, which leverages temporal consistency, while allowing for variations in the order of actions. Our model accounts for both monotonic and non-monotonic sequences and handles background frames that should not be aligned. We demonstrate that our approach consistently outperforms the state-of-the-art in self-supervised sequential action representation learning. |

|
In this paper, we propose a method to collect a dataset of two hands manipulating objects for first person interaction recognition. We provide a rich set of annotations including action labels, object classes, 3D left & right hand poses, 6D object poses, camera poses and scene point clouds. We further propose the first method to jointly recognize the 3D poses of two hands manipulating objects and a novel topology-aware graph convolutional network for recognizing hand-object interactions. |
|
We develop an effective method for low-shot transfer learning for first-person action classification. We leverage independently trained local visual cues to learn representations that can be transferred from a source domain providing primitive action labels to a target domain with only a handful of examples. |

|
We present a method for 3D reconstruction of instructional videos and localizing the associated narrations in 3D. Our method is resistant to the differences in appearance of objects depicted in the videos and computationally efficient. |

|
In this paper, we propose a new method for dense 3D reconstruction of hands and objects from monocular color images. We further present a self-supervised learning approach leveraging photo-consistency between sparsely supervised frames. |

|
We present HoloLens 2 Research Mode, an API anda set of tools enabling access to the raw sensor streams. We provide an overview of the API and explain how it can be used to build mixed reality applications based onprocessing sensor data. We also show how to combine theResearch Mode sensor data with the built-in eye and handtracking capabilities provided by HoloLens 2. |
|
We study the problem of reconstructing the template-aligned mesh for human body estimation from unstructured point cloud data and propose a new dedicated human template matching process with a point-based deep-autoencoder architecture, where consistency of surface points is enforced and parameterized with a specialized Gaussian Process layer, and whose global consistency and generalization abilities are enforced with adversarial training. |

|
In this work, we propose, for the first time, a unified method to jointly recognize 3D hand and object poses, and their interactions from egocentric monocular color images. Our method jointly estimates the hand and object poses in 3D, models their interactions and recognizes the object and activity classes with a single feed-forward pass through a neural network. |
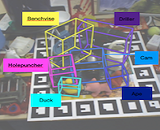
|
We introduce a new deep learning architecture that naturally extends the single-shot 2D object detection paradigm to 6D object pose estimation. It demonstrates state-of-the-art accuracy with real-time performance and is at least 5 times faster than the existing methods (50 to 94 fps depending on the input resolution). |
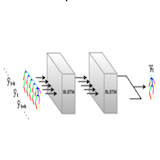
|
We propose an efficient Long-Short-Term-Memory (LSTM) network for enforcing consistency of 3D human pose predictions across temporal windows. |
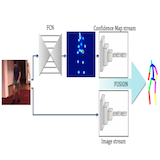
|
We introduce an approach to learn where and how to fuse the streams of a two-stream convolutional neural network operating on different input modalities for 3D human pose estimation. |

|
We propose to jointly model 2D uncertainty and leverage 3D image cues in a regression framework for reliable monocular 3D human pose estimation. |
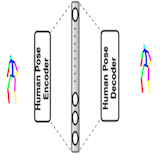
|
We introduce a Deep Learning regression architecture for structured prediction of 3D human pose from monocular images that relies on an overcomplete auto-encoder to learn a high-dimensional latent pose representation and account for joint dependencies. |
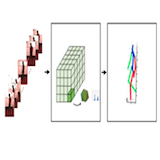
|
We propose to predict the 3D human pose from a spatiotemporal volume of bounding boxes. We further propose a CNN-based motion compensation method that increases the stability and reliability of our 3D pose estimates. |

|
We propose an efficient approach to exploiting motion information from consecutive frames of a video sequence to recover the 3D pose of people. Instead of computing candidate poses in individual frames and then linking them, as is often done, we regress directly from a spatio-temporal block of frames to a 3D pose in the central one. |

|
We introduce an efficient approach to approximate a set of nonseparable convolutional filters by linear combinations of a smaller number of separable ones. We demonstrate that this greatly reduces the computational complexity at no cost in terms of performance for image recognition tasks with convolutional filters and CNNs. |

|
We propose a technique for improving the performance of L1-based image denoising in the steerable wavelet domain. Our technique, which we call consistency, refers to the fact that the solution obtained by the algorithm is constrained to the space spanned by the basis functions of the transform, which results in a certain norm equivalence between image-domain and wavelet-domain estimations. |
|
(*: indicates equal contribution) |
|
|

|
|

|
|
|
|
 |
Gesture recognition based on likelihood of interaction
Multi-modal sensor based process tracking and guidance
Action recognition
Action classification based on manipulated object movement
Predicting three-dimensional articulated and target object pose
Spatially consistent representation of hand motion
Method, System and Device for Direct Prediction of 3D Body Poses from Motion Compensated Sequence |
|
|
 |
Deep Learning, TA, 2018 Computer Vision, TA, 2016, 2017 Numerical Methods for Visual Computing, TA, 2016 Programmation (C/C++) / (Java), TA, 2013, 2015 Principles of Digital Communications, TA, 2013 Circuits and Systems I/II, TA, 2011, 2012, 2013 |
|
pronunciation of my name, Buğra / website template from Jon Barron |